Bohužel ani po hodinách práce nemůžu tvrdit, že bych s tímto nástrojem dokázala levou zadní pracovat :-)
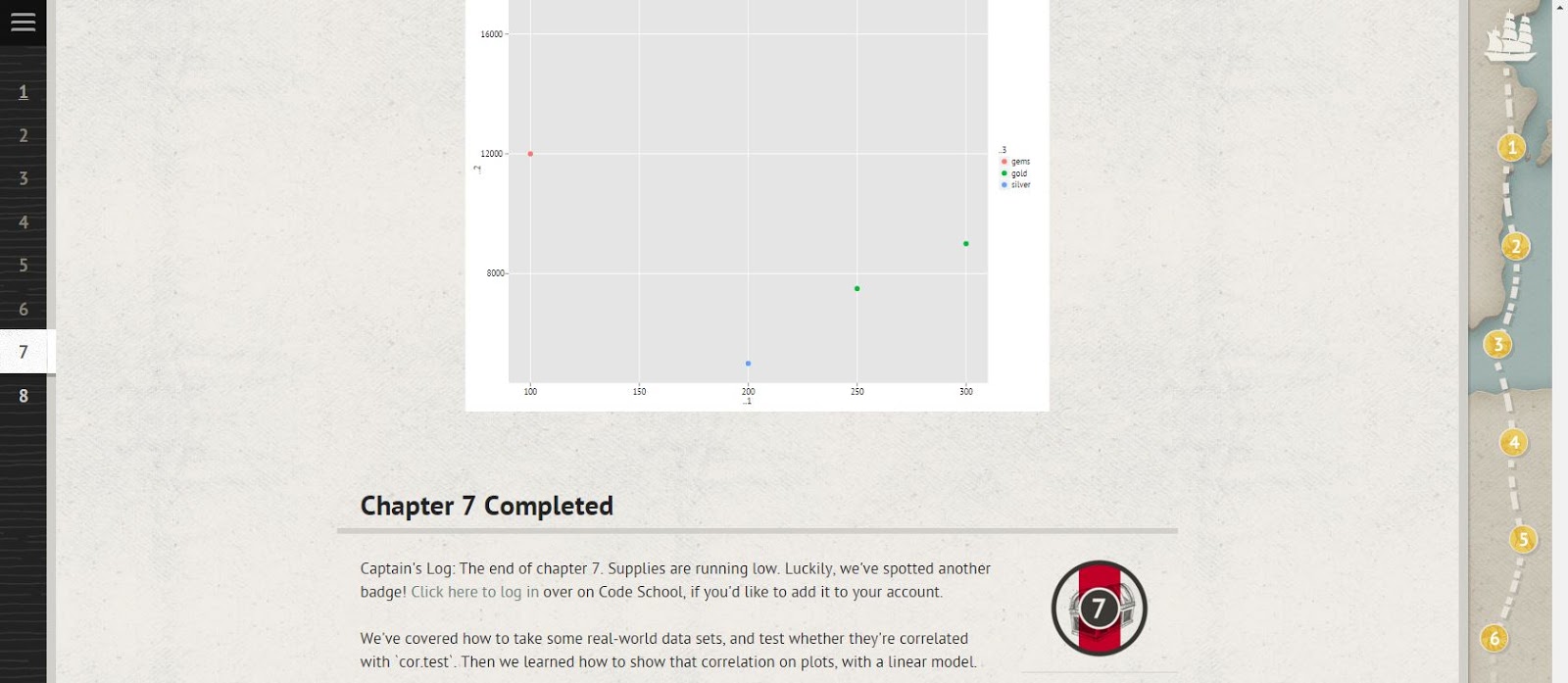
Celá práce se skládala z devíti úkolů, které podle mě byly odlišně náročné.
Zápis úkolu v .R:
# 1. Udelejte z nich data.frame
companiesData <- data.frame(company, fy, profit, revenue)colnames(companiesData) = c("company", "fy", "profit", "revenue")
str(companiesData)
# ---------------------------------------
# 2. Prevedte fy na factor.companiesData$fy <- factor(fy, ordered = TRUE)
str(companiesData)
# ---------------------------------------
# 3. Vypiste jen hodnoty pro firmu Apple
companiesData[company == "Apple",]
# ---------------------------------------
# 4. Pridejte dalsi sloupec margin, ktery bude obsahovat marzi v procentech
margin = c(companiesData$profit/companiesData$revenue*100)
companiesData[5] = margin
colnames(companiesData)[5] = c("margin")
companiesData
# ---------------------------------------
# 5. Pomoci funkce max() najdete historicky nejvetsi marzi
max(companiesData$margin)
# ---------------------------------------
# 6. Jaka firma v jakem roce ji mela?
companiesData[margin == max(companiesData$margin), 1:2]
# ---------------------------------------
# 7. Vytvorte novy data.frame obsahujici jen data pro apple
apple <- companiesData[company == "Apple"]apple
apple <- companiesData[company == "Apple",]
apple
# ---------------------------------------
# 8. Vykreslete sloupcovy graf revenue pro Apple po letech s nadpisem "Revenue of Apple by year"
barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "cyan")
# ---------------------------------------
# 9. Do grafu vepiste vodorovnou modrou caru, ktera urcuje revenue google v roce 2012
h = companiesData$revenue[companiesData == "Google" & companiesData$fy == "2012"]
h
abline (h, 0, col = "blue")
# 1. Udelejte z nich data.frame
> companiesData <- data.frame(company, fy, profit, revenue)
> colnames(companiesData) = c("company", "fy", "profit", "revenue")
> str(companiesData)
'data.frame': 9 obs. of 4 variables:
$ company: Factor w/ 3 levels "Apple","Google",..: 1 1 1 2 2 2 3 3 3
$ fy : num 2010 2011 2012 2010 2011 ...
$ profit : num 14013 25922 41733 8505 9737 ...
$ revenue: num 65225 108249 156508 29321 37905 ...
> # ---------------------------------------
> # 2. Prevedte fy na factor.
> companiesData$fy <- factor(fy, ordered = TRUE)
> str(companiesData)
'data.frame': 9 obs. of 4 variables:
$ company: Factor w/ 3 levels "Apple","Google",..: 1 1 1 2 2 2 3 3 3
$ fy : Ord.factor w/ 3 levels "2010"<"2011"<..: 1 2 3 1 2 3 1 2 3
$ profit : num 14013 25922 41733 8505 9737 ...
$ revenue: num 65225 108249 156508 29321 37905 ...
> # ---------------------------------------
> # 3. Vypiste jen hodnoty pro firmu Apple
> companiesData[company == "Apple",]
company fy profit revenue
1 Apple 2010 14013 65225
2 Apple 2011 25922 108249
3 Apple 2012 41733 156508
> # ---------------------------------------
> # 4. Pridejte dalsi sloupec margin, ktery bude obsahovat marzi v procentech
> margin = c(companiesData$profit/companiesData$revenue*100)
> companiesData[5] = margin
> colnames(companiesData)[5] = c("margin")
> companiesData
company fy profit revenue margin
1 Apple 2010 14013 65225 21.48409
2 Apple 2011 25922 108249 23.94664
3 Apple 2012 41733 156508 26.66509
4 Google 2010 8505 29321 29.00651
5 Google 2011 9737 37905 25.68790
6 Google 2012 10737 50175 21.39910
7 Microsoft 2010 18760 62484 30.02369
8 Microsoft 2011 23150 69943 33.09838
9 Microsoft 2012 16978 73723 23.02945
> # ---------------------------------------
> # 5. Pomoci funkce max() najdete historicky nejvetsi marzi
> max(companiesData$margin)
[1] 33.09838
> # ---------------------------------------
> # 6. Jaka firma v jakem roce ji mela?
> companiesData[margin == max(companiesData$margin), 1:2]
company fy
8 Microsoft 2011
> # ---------------------------------------
> # 7. Vytvorte novy data.frame obsahujici jen data pro apple
> apple <- companiesData[company == "Apple"]
> apple
company fy profit
1 Apple 2010 14013
2 Apple 2011 25922
3 Apple 2012 41733
4 Google 2010 8505
5 Google 2011 9737
6 Google 2012 10737
7 Microsoft 2010 18760
8 Microsoft 2011 23150
9 Microsoft 2012 16978
> apple <- companiesData[company == "Apple",]
> apple
company fy profit revenue margin
1 Apple 2010 14013 65225 21.48409
2 Apple 2011 25922 108249 23.94664
3 Apple 2012 41733 156508 26.66509
> # ---------------------------------------
> # 8. Vykreslete sloupcovy graf revenue pro Apple po letech s nadpisem "Revenue of Apple by year"
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy)
> # ---------------------------------------
> # 9. Do grafu vepiste vodorovnou modrou caru, ktera urcuje revenue google v roce 2012
> h = companiesData$revenue[companiesData == "Google" & companiesData$fy == "2012"]
> h
[1] 50175
> abline (h, 0, col = "blue")
> # 8. Vykreslete sloupcovy graf revenue pro Apple po letech s nadpisem "Revenue of Apple by year"
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "pink")
> abline (h, 0, col = "blue")
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "green")
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "purple")
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "7e00ff")
> barplot(apple$revenue, main = "Revenue of Apple by year", names.arg= apple$fy, col = "cyan")
> # ---------------------------------------
> # 9. Do grafu vepiste vodorovnou modrou caru, ktera urcuje revenue google v roce 2012
> h = companiesData$revenue[companiesData == "Google" & companiesData$fy == "2012"]
> h
[1] 50175
> abline (h, 0, col = "blue")
A konečně odkaz na celý soubor je zde :-)
Jediné co mi opravdu vidělo byl fakt, že jakmile jsem soubor uložila, aplikaci zavřela a následně ji otevřela, celá konzele byla smazaná a musela jsem ji nahrávat znovu.